首页 > 自然语言处理 > 正文
相似的问题能用相同问题回答
对于给定的输入,分类被认为是潜在候选的排序问题
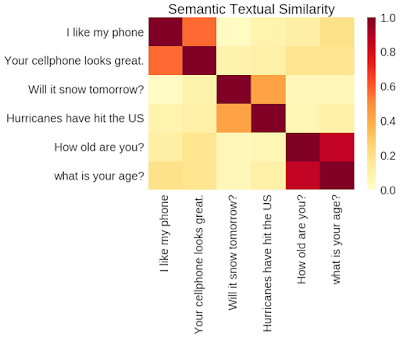
TensorFlow Hub Universal Sentence Encoder输出的句子相似度矩阵
“Universal Sentence Encoder”中的多任务训练。 多项任务以及任务结构共享编码层
原创文章,转载请注明出处!
本文链接:http://youran.tech/posts/Advances-in-Semantic-Textual-Similarity.html
谷歌在文本语义相似中的进展
标签:nlp本文翻译得是Advances in Semantic Textual Similarity。
基于神经网络的自然语言理解研究最近发展迅速,尤其在文本语义表示方面,使得一些新颖的产品比如Smart Compose和Talk to Books变得可能。这类产品能够提高多项自然语言任务的性能,比如建立强悍的文本分类器,即使在少至100个标记文本也能表现良好。
下面将介绍两篇谷歌在语义表示研究中的最新论文,同时也介绍了两个新的模型,这两个模型可以在TensorFlow Hub上下载。通过这两个模型我们希望开发者们能开发出一些令人惊奇的应用。
文本语义相似度
在“Learning Semantic Textual Similarity from Conversations”一文中我们引进了一种新的方法,这种方法能够学习到句子的向量表示用于计算语句的相似度。灵感来源于如果两个句子的回答类似那么他们应该是相似的。比如“How old are you?”和“What is your age?”都是关于年龄的问题, 都可以用 “I am 20 years old”。相反“How are you?”和“How old are you?”包含几乎相同的单词,但是他们的含义不同回答也是不同的。
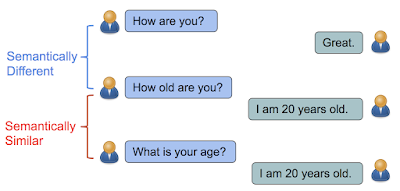
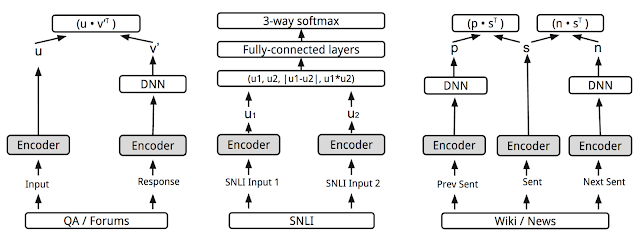
本文通过回复分类任务来解决语义相似问题:给定会话,我们希望将随机选择的很多回复正确的进行分类。但是最终的目标是学习到一个能够返回自然语言多种关系的编码表示模型,包括相似度和相关性。通过添加其他预测任务 (本文是the SNLI entailment dataset)并强制共享编码层, 这样做在the STSBenchmark (语句相似数据集) and CQA task B (问题对相似数据集)两个数据集上相似度计算有了更好的性能. 这是因为语句在逻辑上的蕴意跟简单的对比极大的不同,并能提供更复杂的语义表示。

Universal Sentence Encoder
在 “Universal Sentence Encoder”一文中, 我们介绍了一个模型,这个模型通过添加多任务并像类似skip-thought模型(这个模型预测给定区域的文本的句子)那样进行联合训练拓展了多任务训练,该模型将在下文中介绍。然而,相对于原始skip-thought模型中的编码-解码架构,我们通过共享编码器驱动预测任务的方式只使用了编码部分。 通过这种方式,训练时间大幅缩短,极大的提升了一些迁移任务比如情感识别和语义相似分类任务。提供单个编码器的目标在于能够为大量的应用提供支持成为可能,包括短语检测,短语关联,聚类和自定义文本分类。
正如我们的论文中描述的一样, Universal Sentence Encoder模型一种是使用deep average network (DAN)编码器, 第二种是使用注意力网络 Transformer。
模型结构越复杂, 模型的性能比简单的DAN模型在情感和相似度分类任务上表现更好, 但是对于短句将会更慢一些. 然而, Transformer的运算时间随着句子的长度增加和增加,DAN网络则变化很小。
新模型
此外我们在TensorFlow Hub上分享了两个Universal Sentence Encoder模型:the Universal Sentence Encoder - Large 以及 Universal Sentence Encoder - Lite. 这两个模型输出的是不定长句子的语义表示,能够用于语义相似计算,语义关联,分类,自然语言文本的聚类。
-
大的模型使用Transformer训练,这在第二篇论文中叙述了。目的在于生成准确的语义表示。
-
轻量级模型使用的是句子中的词构成的词典,以减小模型的大小,目标在于较少计算资源的需求,以用于cpu或者浏览器、嵌入式设备。
很高兴能够跟大家分享我们的研究,以及共享预训练的模型。我们相信本文只是开始,更多的重量级研究课题将会得到解决,比如将本技术扩展到多语言。在接下来的工作里,我们将希望能够在篇章级,文档级别去理解文本语言。达成这些目标之后,得到一个真正的‘万能’编码器将变得可能。
Acknowledgements
Daniel Cer, Mario Guajardo-Cespedes, Sheng-Yi Kong, Noah Constant for training the models, Nan Hua, Nicole Limtiaco, Rhomni St. John for transferring tasks, Steve Yuan, Yunhsuan Sung, Brian Strope, Ray Kurzweil for discussion of the model architecture. Special thanks to Sheng-Yi Kong and Noah Constant for training the Lite model.
原创文章,转载请注明出处!
本文链接:http://youran.tech/posts/Advances-in-Semantic-Textual-Similarity.html