1.Training on GPU
2017-12-29
import torch
import torch.nn as nn
import torch.autograd as autograd
import torch.optim as optim
#how to validate cuda available
if torch.cuda.is_available():
print('cuda is on')
else:
print('cuda is off')
#if available
#allocate tensor to default device
x=torch.LongTensor(1)
if torch.cuda.is_available():
x.cuda()
if torch.is_tensor(x):
print('x is a tensor')
print(torch.cuda.device_count())
#transfer tensor to a specified device
y=torch.LongTensor(1).cuda(0)
#you can use tensor.get_device() to show which device tensor located
print(y.get_device())
#gernerally,specified context manager to run code
with torch.cuda.device(0):
x=torch.cuda.LongTensor(1)
x=torch.randn(1,2).cuda(0)#even in context you can specified a device to locate tensor
#device-agnostic code
isCuda=torch.cuda.is_available()
x=torch.Tensor(1,2)
if isCuda:
x=x.cuda()
print(torch.eye(3,4))
阅读全文 »
5.Word2Vec
2017-12-26
最简单的word2vec训练方式:
# import modules & set up logging
import gensim
#build for sentences list
sentences = [['first', 'sentence'], ['second', 'sentence']]
# train word2vec on the two sentences
model = gensim.models.Word2Vec(sentences, min_count=1,workers=4)
如果文本太多,可以使用一种优化内存的加载方法:
#build from files
import os
class MemorySentences(object):
def __init__(self,path):
self.path=path
def __iter__(self):
for filename in os.listdir(self.path):
for line in open(os.path.join(self.path,filename),'r'):
yield list(line)
corpus=MemorySentences('../data/wiki_zh/')
model = gensim.models.Word2Vec(corpus, min_count=1,workers=4)
模型的保存和加载:
#model save and load
model.save('/tmp/mymodel')
new_model = gensim.models.Word2Vec.load('/tmp/mymodel')
model = gensim.models.Word2Vec.load_word2vec_format('/tmp/vectors.txt', binary=False)
# using gzipped/bz2 input works too, no need to unzip:
model = gensim.models.Word2Vec.load_word2vec_format('/tmp/vectors.bin.gz', binary=True)
使用方法:
#usage
model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1)
#[('queen', 0.50882536)]
model.doesnt_match("breakfast cereal dinner lunch".split())
'cereal'
model.similarity('woman', 'man')
#0.73723527
阅读全文 »
4.Similarity and Queries
2017-12-25
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
from gensim import corpora,models,similarities
import os
if os.path.exists('./model/dictionary.m'):
dictionary=corpora.Dictionary.load('./model/dictionary.m')
corpus=corpora.MmCorpus('./model/corpra.mms')
lsi_model=models.LsiModel(corpus=corpus,id2word=dictionary,num_topics=5)
doc='你今天心情怎么样'
vec_doc=dictionary.doc2bow(list(doc))
vec_lsi=lsi_model[vec_doc]
print(vec_lsi)
#build similarity matrix
sim_matrix=similarities.MatrixSimilarity(lsi_model[corpus])
sim_matrix.save('./model/lsi_sim.m')
del(sim_matrix)
sim_matrix=similarities.MatrixSimilarity.load('./model/lsi_sim.m')
sims=sim_matrix[vec_lsi]
sims = sorted(enumerate(sims), key=lambda item: -item[1])
print(sims)
阅读全文 »
3.Topic and Transformations
2017-12-25
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
from gensim import corpora,models,similarities
import os
if os.path.exists('./model/dictionary.m'):
dictionary=corpora.Dictionary.load('./model/dictionary.m')
print(dictionary)
corpus=corpora.MmCorpus('./model/corpra.mms')
print('load dictionary and corpus done')
#build tf-idf model
tfidf_model=models.TfidfModel(corpus=corpus, normalize=True)
tfidf_corpus=tfidf_model[corpus]
# for corpra in tfidf_corpus:
# print(corpra)
#build lsi model
lsi_model=models.LsiModel(corpus=tfidf_corpus,id2word=dictionary,num_topics=4)
lsi_corpus=lsi_model[corpus]
# for corpra in lsi_corpus:
# print(corpra)
print(lsi_model.show_topics(2))
# lsi_model.add_documents([])#add new document
# lsi_vec = lsi_model[]#transform to vector
#random projection model
rp_model = models.RpModel(tfidf_corpus, num_topics=500)
#latent Dirichlet Allocation
lda_model = models.LdaModel(tfidf_corpus, id2word=dictionary, num_topics=100)
#Hierarchical Dirichlet Process
hdp_model = models.HdpModel(tfidf_corpus, id2word=dictionary)
else:
print('file not exsit')
阅读全文 »
2.Corpora and Vector Spaces
2017-12-24
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# 加载语料库
documents =[line.split('$$$')[0] for line in open('../data/corpus.txt','r').readlines()]
print(documents[:5])
# 移除停用词
stopwords='啊呢吗的'
texts=[[word for word in document if word not in stopwords] for document in documents]
print(texts[:5])
# 构造词频
from collections import defaultdict
freq=defaultdict(int)
for text in texts:
for word in text:
freq[word]+=1
# 移除出现次数少于1次的词
texts=[ [word for word in text if freq[word]>1] for text in texts]
print(texts[:5])
# 构造词典
from gensim import corpora
dictionary=corpora.Dictionary(texts)
print(dictionary)
print(dictionary.token2id)
# 本地持久化
dictionary.save('./model/dictionary.m')
# 文档向量化
new_text='今天天气比较好,适合出去旅游'
new_vec=dictionary.doc2bow(list(new_text))
print(new_vec)
# 文档序列化
corpus=[dictionary.doc2bow(text) for text in texts]
corpora.MmCorpus.serialize('./model/corpra.mms',corpus)
corpus = corpora.MmCorpus('/tmp/corpus.mms')
corpora.SvmLightCorpus.serialize('/tmp/corpus.svmlight', corpus)
corpus = corpora.SvmLightCorpus('/tmp/corpus.svmlight')
corpora.BleiCorpus.serialize('/tmp/corpus.lda-c', corpus)
corpus = corpora.BleiCorpus('/tmp/corpus.lda-c')
corpora.LowCorpus.serialize('/tmp/corpus.low', corpus)
corpus = corpora.LowCorpus('/tmp/corpus.low')
# memory friendly 1
class MyCorpus:
def __iter__(self):
for line in open('../data/corpus.txt','r'):
yield dictionary.doc2bow(list(line))
corpus_friendly=MyCorpus()
# memory friendly 2
from six import iteritems
once_ids = [tokenid for tokenid, docfreq in iteritems(dictionary.dfs) if docfreq == 1]#document frequencies: tokenId -> in how many documents this token appeared
#corpus compacty
dictionary.filter_tokens(once_ids)#remove id=1
dictionary.compactify()#remove gaps between id
阅读全文 »
1.Introduction
2017-12-24
Gensim提供对计算机和调用者友好,自动从文档中抽取语义主题的免费Python库。 Gensim处理原始数据、非结构化文本数据。Gensim中使用的算法包括潜在语义分析、潜在狄利克雷分布和随机预测,通过训练文档中的词的共现分布情况发现文本语义结构。这些算法是非监督的,在使用的时候不需要输入额外的数据,只需要输入语料即可。 一旦这些语料的统计分布模式确定,即可以比较不同文档之间的主题相似度。
特性
- 内存无关,语料库不会完整的加载进如村。
- 高效的实现若干流向的向量空间算法,包括tf-idf,潜在语义分析、LDA、随机预测;并且对新增算法也很友好
- 对流行的数据格式进行了封装和处理
- 文档的相似度查询
核心概念
Gensim的核心概念包括:语料库、向量和模型。
语料库
文档集合,用于推断文档结构和文档主题等,也叫做训练语料库。训练语料库训练好之后可以用于计算新文档的主题。训练语料库不需要进行人工标注。
向量
在向量空间中,每一个文档都用一个特征数组表示。例如,下面的每一个特征都用一对问答对表示:
1.How many times does the word splonge appear in the document? 0.
2.How many paragraphs does the document consist of? 2.
3.How many fonts does the document use? 5.
每一个问题用整数1,2,3表示,那么整个文档可以表示为:(1,0),(2,2),(3,5)。进一步的,可以省略问题ID,直接表示为(0,2,5)。这样文档就可以用一个三维数组表示了。
稀疏向量
通常情况下,文档中的大多数特征都是0。为了节省空间,通常在表示文档的时候将特征为0的维度省略,比如:(2,2),(3,5)。虽然省略了0,但是因为特征都是已知的,所以在恢复的时候可以把为0的特征恢复。
模型
模型从训练语料中学习得到,将原始语料库的向量表示转换为另一个向量。
阅读全文 »
3.Cypher
2017-10-24
1.Pattern
Neo4j中的图由节点(Node)和关系(Relation)组成,节点和关系也可以具有属性。节点代表的是实体,比如概念、事件、地点和事物。关系将节点连接起来。
节点和关系是图的基本单元,但是真正让图表示复杂知识的是连接起来的节点和关系构成的patterns。单一的节点和关系仅仅只能携带少量的信息但是pattern却可以携带或表示复杂的信息。
Cypher是Neo4j的查询语言就是基于pattern。通常pattern用来匹配期望找到的图结构,一旦找到或者创建,就可以进行进一步处理。
Cypher中简单的pattern比如:a Person LIVES_IN a City or a City is PART_OF a Country
或者更为复杂一点的:(:Person) -[:LIVES_IN]-> (:City) -[:PART_OF]-> (:Country)
Cypher的长处在于擅长识别各种给定的模式(pattern)。就跟人脑一样,比如人脑就很擅长识别图片中的人、物体等,因为人、物体都具备一定的模式。
Cypher跟SQL语言类似,有比如MATCH,WHERE,DELETE之类的关键字。
2.Node语法
Node使用一对括号表示:
()
((matrix))
(:Movie)
(matrix:Movie)
(matrix:Movie {title: "The Matrix"})
(matrix:Movie {title: "The Matrix", released: 1997})
Movie是Node的标签,表明节点的类型。不同的标签可以组成不同的模式,比如Movie和Actor就可以组成一种模式。Neo4j的节点使用标签索引的,每一个索引由标签和属性组成。
节点的属性由大括号包含一系列key/value。比如
{title: "The Matrix", released: 1997}
Relation语法
Cypher中--表示无方向性的关系,<--,-->表示指向性的关系,[....]表示对关系的说明,可以是变量、属性等。
-->
-[role]->
-[:ACTED_IN]->
-[role:ACTED_IN]->
-[role:ACTED_IN {roles: ["Neo"]}]->
ACTED_IN是关系的标签,指明关系的类型。role是关系变量,可以在别处使用。roles是属性值,和节点的属性一样。
Pattern语法
(keanu:Person:Actor {name: "Keanu Reeves"} )-[role:ACTED_IN {roles: ["Neo"] } ]->(matrix:Movie {title: "The Matrix"} )
Pattern指明在图中符合给定pattern的节点以及连接的关系。 Pattern还可以被声明为一个变量:
acted_in = (:Person)-[:ACTED_IN]->(:Movie)
Cypher示例
打开命令行执行:
sudo bin/neo4j console
打开浏览器打开:
http://localhost:7474/browser/
添加:
CREATE (:Movie { title:"The Matrix",released:1997 })
执行完毕可以看到:

如果创建之后需要返回值:
CREATE (p:Person { name:"Keanu Reeves", born:1964 })
RETURN p
执行完毕可以看到:

更为复杂的一个例子:
CREATE (a:Person { name:"Tom Hanks",
born:1956 })-[r:ACTED_IN { roles: ["Forrest"]}]->(m:Movie { title:"Forrest Gump",released:1994 })
CREATE (d:Person { name:"Robert Zemeckis", born:1951 })-[:DIRECTED]->(m)
RETURN a,d,r,m

查找
比方说查找所有的Movie:
MATCH (m:Movie)
RETURN m

也可以找某个具体的人:
MATCH (p:Person { name:"Keanu Reeves" })
RETURN p

还可以查找某个关系:
MATCH (p:Person { name:"Tom Hanks" })-[r:ACTED_IN]->(m:Movie)
RETURN m, r

创建新的pattern
MATCH (p:Person { name:"Tom Hanks" })
CREATE (m:Movie { title:"Cloud Atlas",released:2012 })
CREATE (p)-[r:ACTED_IN { roles: ['Zachry']}]->(m)
RETURN p,r,m

MERGE
Merge表示为节点或者关系添加新的pattern或属性。
添加新的属性:
MERGE (m:Movie { title:"Cloud Atlas" })
ON CREATE SET m.released = 2012
RETURN m

添加新的关系:
MATCH (m:Movie { title:"Cloud Atlas" })
MATCH (p:Person { name:"Tom Hanks" })
MERGE (p)-[r:ACTED_IN]->(m)
ON CREATE SET r.roles =['Zachry']
RETURN p,r,m

添加新的节点和关系:
CREATE (y:Year { year:2014 })
MERGE (y)<-[:IN_YEAR]-(m10:Month { month:10 })
MERGE (y)<-[:IN_YEAR]-(m11:Month { month:11 })
RETURN y,m10,m11

条件选择
#1 WHERE
MATCH (m:Movie)
WHERE m.title = "The Matrix"
RETURN m
#2 WHERE
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie)
WHERE p.name =~ "K.+" OR m.released > 2000 OR "Neo" IN r.roles
RETURN p,r,m
#3 NOT
MATCH (p:Person)-[:ACTED_IN]->(m)
WHERE NOT (p)-[:DIRECTED]->()
RETURN p,m
#4 ALIAS
MATCH (p:Person)
RETURN p, p.name AS name, toUpper(p.name), coalesce(p.nickname,"n/a") AS nickname, { name: p.name,
label:head(labels(p))} AS person
#5 COUNT
MATCH (:Person)
RETURN count(*) AS people
OR
RETURN count(DISTINCT role)
MATCH (actor:Person)-[:ACTED_IN]->(movie:Movie)<-[:DIRECTED]-(director:Person)
RETURN actor,director,count(*) AS collaborations
#6 ORDER
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
RETURN a,count(*) AS appearances
ORDER BY appearances DESC LIMIT 10;
#7 COLLECT
MATCH (m:Movie)<-[:ACTED_IN]-(a:Person)
RETURN m.title AS movie, collect(a.name) AS cast, count(*) AS actors
#8 UNION
MATCH (actor:Person)-[r:ACTED_IN]->(movie:Movie)
RETURN actor.name AS name, type(r) AS acted_in, movie.title AS title
UNION
MATCH (director:Person)-[r:DIRECTED]->(movie:Movie)
RETURN director.name AS name, type(r) AS acted_in, movie.title AS title
#9 WITH
MATCH (person:Person)-[:ACTED_IN]->(m:Movie)
WITH person, count(*) AS appearances, collect(m.title) AS movies
WHERE appearances > 1
RETURN person.name, appearances, movies
查询的结果可能是数字、字符串、或者列表、数组。
约束和索引
# UNIQUE
CREATE CONSTRAINT ON (movie:Movie) ASSERT movie.title IS UNIQUE
# INDEX
CREATE INDEX ON :Actor(name)
CREATE (actor:Actor { name:"Tom Hanks" }),(movie:Movie { title:'Sleepless IN Seattle' }),
(actor)-[:ACTED_IN]->(movie);
阅读全文 »
2.Neo4j相关概念
2017-10-17
1.Neo4j graph database
一个简单的Neo4j数据库的样子如下所示:
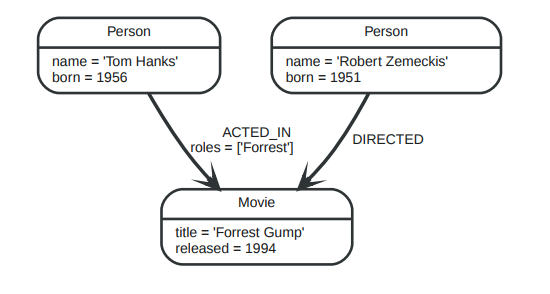
它包含节点person和movie,关系ACTED_IN和DIRECTED,以及它们的属性name,born,title,released。
2.Node:
最简单的一个Node就像下面的样子:

它包含一个值为Forrest Gump的属性title。
下面再新建2个节点并分别添加2个属性,以及为上一个节点添加一个属性released。
3.Relationship
关系是图数据库的一个核心特性。关系连接2个节点,一个是源节点,一个是目标节点。正因为有了关系才使得节点构成了丰富又复杂的结构,可以是:列、树或者复合行的实体。
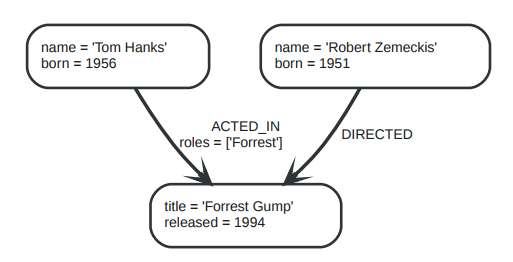
上图中关系类型有:ACTED_IN和DIRECTED。关系ACTED_IN的属性roles值为一个数组。
对于ACTED_IN关系来说,节点Tom Hanks是源节点,Forrest Gump是目标节点。我们可以这么形容:节点Tom Hanks有一个指向关系,Forrest Gump有一个被指向关系。
关系的方向在搜索的时候是等价的,也就是说是双向的。
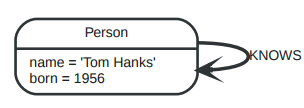
关系还可以指向节点自身。
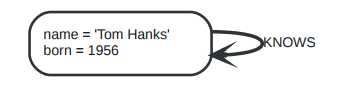
这表示着Tom Hanks KNOWS 他自己。
对于图:
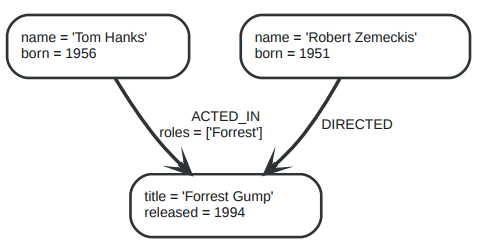
可以得到下表:

上图展示了对于不同的查询角度来说,关系的指向是不同的。
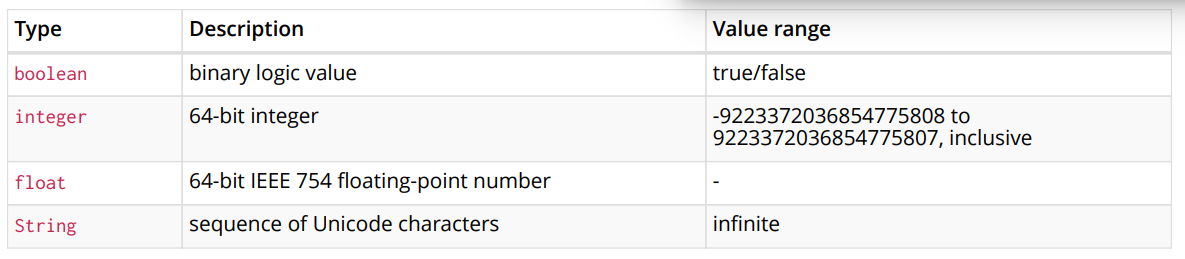
4.属性
属性具有属性名和值,属性名是一个string,值的类型是:
- 数字
- 字符串
- 布尔值
- Point
- 时间类型
- Date
- Time
- LocalTime
- DateTime
- LocalDateTime
- Duration
下图是一个示例:
5.Label
Label对节点进行标记分成不同的集合或者称为类型。比如对于银行账户标记为:Suspended就表示这是封存的账户,对蔬菜标记:Seasonal就表示是当季的。
下面是一个示例:
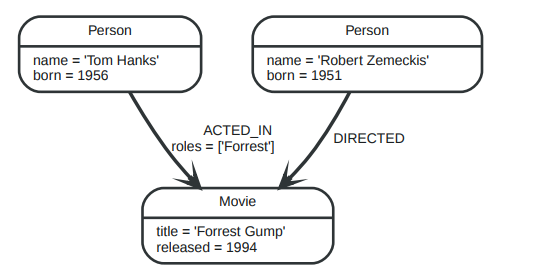
节点也可以有多个label:

注意节点的label也可能是空的。
命名的时候使用驼峰命名法,比如CarOwner.
6.遍历
图遍历是从一个节点出发查找相邻的节点。 Cypher就是用于图查询的类SQL语言。
7.path
依据给定规则搜索到的子图就是一个path:

也可以只是一个节点,此时长度为0
或者长度为1: