首页 > Python > 正文
原创文章,转载请注明出处!
本文链接:http://youran.tech/posts/python-weibo-scrapy.html
如何打造一个个人微博爬虫
标签:python本文介绍使用scrapy爬虫框架打造一个自己的微博客户端。主要包括以下内容:
- 1.介绍如何分析构造微博爬虫;
- 2.使用scrapy进行网页内容提取。
1.分析如何构造爬虫流程
对于大不多数爬虫,首先考虑的应该是从手机端入手,因为手机端的网页相对PC端来说内容更为简洁,并且爬起来容易许多。所以本文爬取的就是微博的手机端网站:https://weibo.cn/。 为了构造所需的爬虫,首先需要分析目标网站的网站结构。以微博为例,打开微博手机端网站输入密码登陆之后进入的就是首页。首页上的内容就是关注的人发布的微博。比如下图:
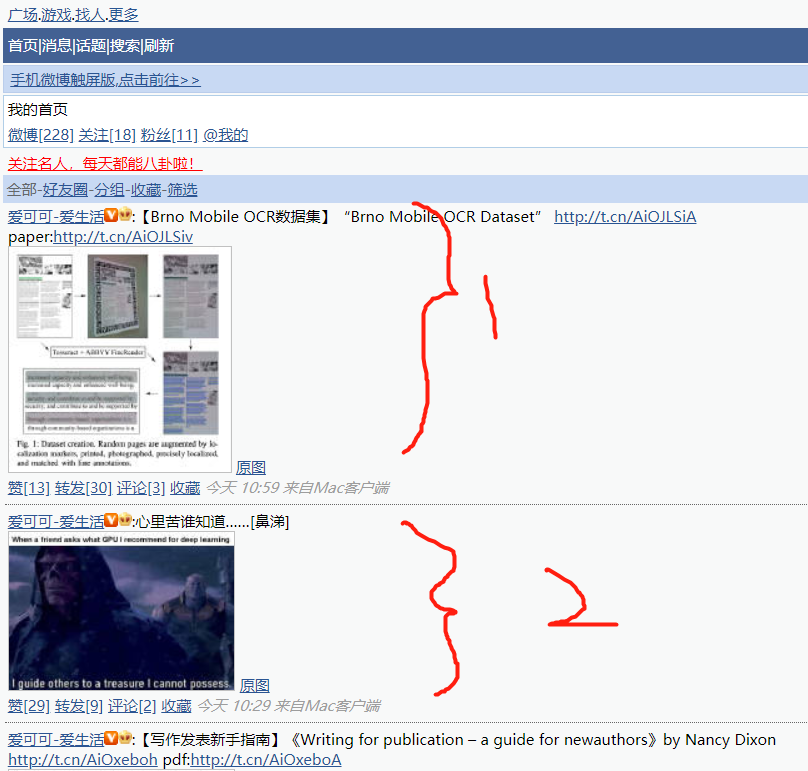
红色的数字1、2就是指一条条关注的人发布的微博。
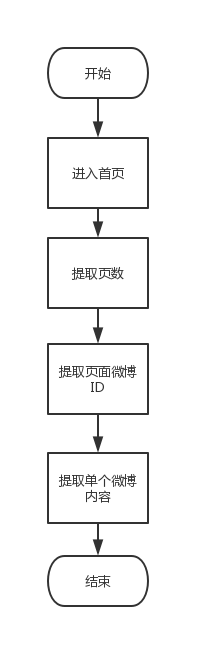
到这里,一个简单的爬取思路就出来了:首先是打开网址;然后是登陆首页;最后就是按照页码顺序把一条条微博提取出来。
用流程图表述为:
2. 使用scrapy进行网页内容提取
本文对微博手机端的分析使用的是Chrome浏览器自带的工具。在浏览器按下F12即可打开。如下图所示:
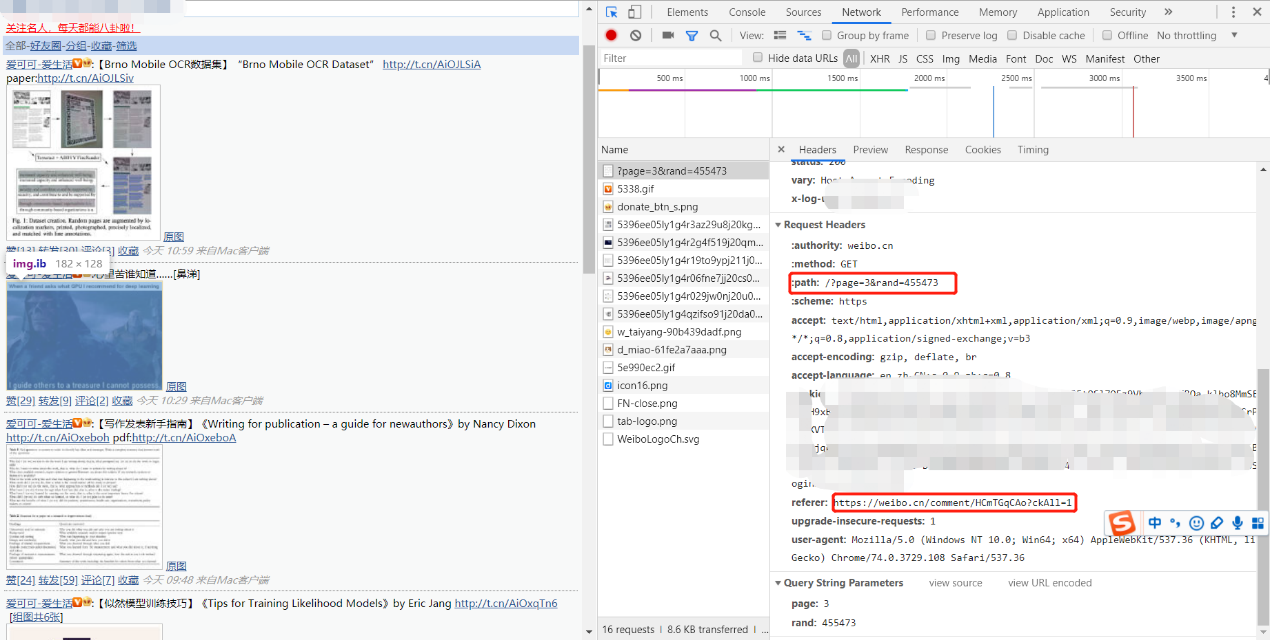
由上图可以得出以下结论:
-
- 个人主页的微博页面的网址构造为:https://weibo.cn?page=页码
-
- 微博ID对应的页面为:https://weibo.cn/comment/ID
-
- 自动登录的cookie(图中模糊部分)
打开任意一条微博ID的页面:
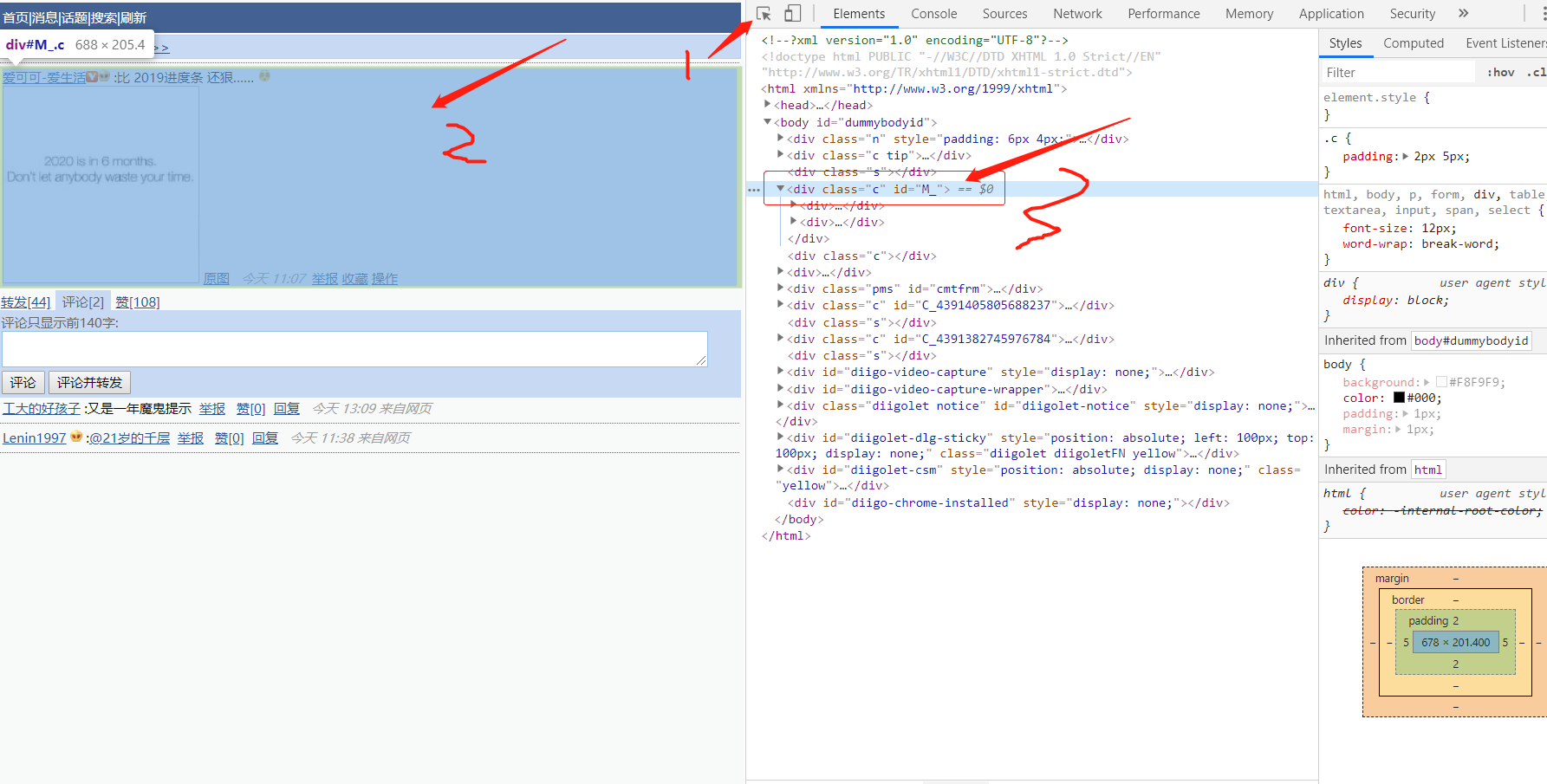
按照上图的箭头点击顺序,可以看到微博内容的标签为<div class=’c’ id=’M_’>,因而根据标签就可以提取到微博的内容了。
上述几个步骤用代码表述为:
def parse(self, response):#解析页码
page_num=0
if response.xpath("//input[@name='mp']") == []:#这里处理微博为空的情况
page_num = 1
else:
page_num = (int)(response.xpath("//input[@name='mp']")[0].attrib['value'])
# https://weibo.cn/?page=2
for i in range(1,page_num+1):#page 1-40
yield response.follow(f'https://weibo.cn/?page={i}', callback=self.parse_id)
def parse_id(self,response):#提取对应页码的微博ID
ids=response.xpath('//div[contains(@id,"M_HC")]/@id').getall()
for id in ids:#parse weibos
#https://weibo.cn/comment/HAwmslrRT
yield response.follow(f'https://weibo.cn/comment/{id.replace(r"M_","")}', callback=self.parse_weibo)
def parse_weibo(self,response):#提取对应微博ID的内容
content=response.xpath('//div[@id="M_"]')[0].xpath('string()').extract()[0]
self.writer.write(content+'\n\n')
以上介绍了构建个人微博客户端的关键步骤,具体可以参考gihtub上的开源代码。
原创文章,转载请注明出处!
本文链接:http://youran.tech/posts/python-weibo-scrapy.html
上篇:
解决Ubuntu下pip3安装TA-Lib失败的问题
下篇:
xpath的语法简介