3.RNN模型
标签:Pytorch, dl本文的目标是实现Elman RNN模型。
Elman RNN模型
模型结构用数学公式表示很简单:
\(h_t=\tanh(w_{ih}*x_t+b_{ih}+w_{hh}*h_{(t-1)}+b_hh)\)
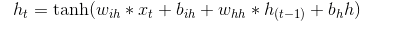
$h_{(t-1)}$表示$t-1$时刻隐层的输出,$x_t$表示$t$时刻的输入,i表示第i层。RNN使用tanh或ReLU作为激活函数。
模型的结构如下图所示:
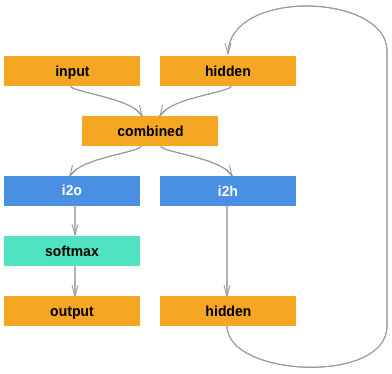
Pytorch中的RNN模型
Pytorch中RNN模型的API为:
class torch.nn.RNN(*args, **kwargs)
1.构造函数参数说明:
| 参数 | 说明 |
|---|---|
| input_size | 输入层输入的特征个数 |
| hidden_size | 隐层输入的特征个数 |
| num_layers | 网络的层数 |
| nonlinearity | 非线性激活函数:‘tanh’或’relu’. 默认: ‘tanh’ |
| bias | False,表示偏置值为0, 默认: True |
| batch_first | True, 表示输入、输出中batch放在参数第一个:(batch, seq, feature) |
| dropout | 非0表示引入Drop层,最后一层除外。 |
| bidirectional | True, 表示双向RNN. 默认: False |
2.输入参数说明:
- input:输入的格式(seq_len, batch, input_size)
- $h_0$:训练开始时隐层的初始状态:$h_0 (num_layers * num_directions, batch, hidden_size)$
batch表示有几个长度为seq_len的序列。
3.输出参数说明:
- output:输出的格式:$output(seq_len, batch, hidden_size* num_directions)$
- $h_n$:n时刻隐层的输出:$h_n (num_layers * num_directions, batch, hidden_size)$
4.中间变量
| 参数 | 说明 |
|---|---|
| weight_ih_l[k] | 模型学习到第k个输入层到隐层的参数,大小为:(input_size x hidden_size) |
| weight_hh_l[k] | 模型学习到第k个隐层到隐层的参数,大小为:(hidden_size x hidden_size) |
| bias_ih_l[k] | 模型学习到第k个输入层到隐层的偏置参数,大小为: (hidden_size) |
| bias_hh_l[k] | 模型学习到第k个隐层到隐层的偏置参数,大小为: (hidden_size) |
5.实例
rnn = nn.RNN(10, 20, 2)
input = Variable(torch.randn(5, 3, 10))
h0 = Variable(torch.randn(2, 3, 20))
output, hn = rnn(input, h0)
原创文章,转载请注明出处!
本文链接:http://youran.tech/posts/pytorch-rnn.html