conda无法安装opencv的解决办法
2020-06-23
在新电脑中用conda命令安装opencv,但不是403错误就是超时。错误如下:
Collecting package metadata (repodata.json): done
Solving environment: failed
Initial quick solve with frozen env failed. Unfreezing env and trying again.
Solving environment: failed
解决的办法是使用pip安装:pip install opencv-python即可解决。
阅读全文 »
如何使用Fiddler进行网络抓包
2020-05-08
最近有个爬虫的需求,需要从网站上自动登录、爬取各种文件,所以就需要自己编写个爬虫程序进行爬取。
爬虫之前首先需要对目标网站进行分析,下面就介绍一下本次项目的一些经验。
1.抓包工具
本次抓包工具使用的是Fiddler,配合浏览器FireFox使用。
原因是Fiddler没有网页标签页的跳转问题,不容易错过网络包,而且FireFox的F12功能可视化做的比chrome好。
1.1安装
在Linux系统中安装fiddler比较方便,基本的命令行就能解决:
wget http://ericlawrence.com/dl/MonoFiddler-v4484.zip
unzip MonoFiddler-v4484.zip
sudo apt-get install mono-complete
mono Fiddler.exe
即可以打开程序主界面
1.2 https配置
这里需要配置两个地方,一个是支持https,一个是配置代理用于手机APP抓包。
支持https配置,在Fiddler中:
-
点击Tools > Fiddler Options > HTTPS.
- 点击 Decrypt HTTPS Traffic box.
- 点击 export root certificate to desktop.完成本部操作可以在桌面看到导出的证书。
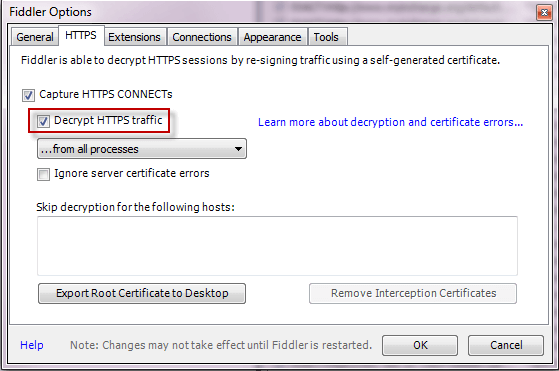
配置好Fiddler对https的支持之后,还需要在firefox中import证书。
路径为:FireFox输入about:preferences#privacy,在页面底部选择View Certificates…,然后在打开的页面中引入即可。
1.3 代理的配置
配置代理的方式也依葫芦画瓢即可:在Fiddler中点击Tools > Fiddler Options > Connections > Allow remote computer connects。
然后记得点击copy browser proxy configuration url.
回到firefox中,地址栏输入about:preferences#general,拉到页面底部选择setting,跳出的页面中选择’'’Automatic proxy configuration URL’’’ 选项,将上一部拷贝的proxy url输入,点击ok完成操作即可。
这一步的操作相当于对网络连接中引入Fiddler,效果图如下:

2.操作
完成上一部的安装和配置就可以开始抓包了。在firefox中进行网页登录之类的操作,Fiddler中讲能够完成看到所有的网络包。如下图所示:

图片中,左侧是网络包,右侧是网络包的详情。网络包详情如下所示:

3.一些trick
-
在实际抓包中,Fiddler还是得配合firefox使用,比如我一般用Fiddler去观察网络包的顺序,理解目标网站的请求顺序。然后用firefox去分析关键的请求。
-
firefox的可视化做的比Fiddler好,所以用firefox去分析具体的请求更方便。比如分析requestheaders,分析cookie
-
在最开始抓包的时候记得清空firefox的缓存和cookies,路径:F12 > storage > cookies.
-
在firefox network选项卡中右键header bar选择显示set-cookie选项卡能够帮助了解cookie是在哪里设置的。
阅读全文 »
解决Bottle中的CORS问题
2020-04-19
最近在将安全帽检测算法发布到web上,网页中需要通过http post方法访问其他服务器的IP,执行操作的时候出现from origin 'null' has been blocked by CORS policy错误。
原因是:web server为了保证安全禁止了资源的跨域访问。
解决办法:
首先google了一些解决办法,试了下发现没有起作用,最后发现是因为网络上的解决办法的bottle版本是老版本,新版本有些规则变了。
所以本文就列出最新版本的解决办法。
解决的办法也简单,只需要给header添加’Access-Control-Allow-Origin’=’*‘即可。参考如下代码:
@route("/upload", method=['POST'])
def hello():
bottle.response.set_header('Access-Control-Allow-Origin', '*')
bottle.response.add_header('Access-Control-Allow-Methods',
'GET, POST, PUT, OPTIONS')
bottle.response.add_header('Access-Control-Allow-Headers',
'Origin, Accept, Content-Type, X-Requested-With, X-CSRF-Token')
另外需要注意的是,bottle中@route(“/upload”, method=[‘POST’])中method中不支持list的写法,如果同时支持POST和GET方法需要分开两行写。 如下:
@route("/upload", method=['POST'])
@route("/upload", method=['GET'])
def hello():
pass
阅读全文 »
如何使用Mongoengine保存文件
2020-01-08
引言
因为文件大小的限制,mongodb中通常使用GridFS进行文件存储。MongoEngine是python中实现对象-文档的映射的包。它基于GridFS提供了用于文件存储的FileField对象,并且文件的操作和python内置文件操作一样。
FileField提供Write、Read、Delete、Replace四种操作。FileField在GridFS中将保存在一个文件中。如果想要覆盖原文件,那么需要进行删除和创建新文件的操作。FileField和文件系统类似,但是一个明显的区别是FileField只能写一次。
使用方法
from mongoengine import Document
from mongoengine import FileField
class Article(Document):
# collection_name参数默认为'fs',当然也可以自定义。
# 自定义方式:FileField(collection_name='images')
upload = FileField()
art = Article()
with open('image.png', 'rb') as image_file:
art.upload.put(image_file, content_type='image/png')
# 如果是网络读取文件,则需要用到StringIO或者使用临时文件
mem_file = StringIO()
mem_file.write(image_content_from_http)
art.upload.put(mem_file, content_type='image/png')
#如果要替换文件则
with open('image.png', 'rb') as image_file:
art.upload.replace(image_file, content_type='image/png')
FileField提供的方法
- get
- new_file
- put
- replace
- write
- writelines
- close
- replace
如果要进行写操作使用
write操作,如果是进行读操作,则使用read操作;如果是进行replace操作,则需要先进行delete操作,然后使用write或者new_file。注意使用write方法之后记得执行close操作对流进行关闭。
list操作
有时候需要进行多文件的读写,比如一次写入多张图片,下面给出一个例子:
from mongoengine import Document
from mongoengine import FileField, EmbeddedDocument, EmbeddedDocumentField
class ArticleImage(EmbeddedDocument):
image = FileField()
class Article(Document):
images = ListField(EmbeddedDocumentField(ArticleImage))
art = Article()
image_1 = ArticleImage()
with open('image1.png', 'rb') as image_file:
image_1.put(image_file, content_type='image/png')
image_2 = ArticleImage()
with open('image2.png', 'rb') as image_file:
image_2.put(image_file, content_type='image/png')
art.images.append(image_1)
art.images.append(image_2)
#读
for img in Article.objects():
pass
阅读全文 »
如何部署分布式框架Celery到远程机器上
2019-11-12
最近做了一个抢票软件用于抢票,开发好了之后分布在4台服务器上运行。实际的开发和部署过程有点繁琐,所以萌生了基于分布式的想法。 了解到python中Celery框架使用得较多,因而本文就学习一下如何部署基于Celery的代码到远程机器上。
Celery中的三个组件
Celery的思想比较简单,就是一个基于消息的分布式框架。核心有三个组件:
- Application: 类似于客户端像服务器不断的请求执行新的任务;
- Worker: 类似于服务器,用于执行任务;
- Broker: 负责通信。
这三个组件组成了Celery的核心部分,一方面客户端不需要了解服务器的实现,只需要通过Broker发送消息即可; 另一方面服务器只需要关心具体的业务,Broker只负责通信。
下面开始逐步搭建一个远程Celery服务。
0、安装必要的包
#安装erlang
wget http://packages.erlang-solutions.com/site/esl/esl-erlang/FLAVOUR_1_general/esl-erlang_20.1-1~ubuntu~xenial_amd64.deb
sudo dpkg -i esl-erlang_20.1-1\~ubuntu\~xenial_amd64.deb
#安装rabbitmq
echo "deb https://dl.bintray.com/rabbitmq/debian xenial main" | sudo tee /etc/apt/sources.list.d/bintray.rabbitmq.list
wget -O- https://www.rabbitmq.com/rabbitmq-release-signing-key.asc | sudo apt-key add -
sudo apt-get update
sudo apt-get install rabbitmq-server
sudo systemctl start rabbitmq-server.service
sudo systemctl enable rabbitmq-server.service
#安装Celery
pip install celery
第一步:添加用户
这一步需要在服务器中进行,添加的目的类似于在服务器添加一个账户,这样就使得客户端能够使用这个账户访问服务器的权限。
# 添加帐号密码
sudo rabbitmqctl add_user <user> <password>
# 添加虚拟主机
sudo rabbitmqctl add_vhost <vhost_name>
# 添加权限
sudo rabbitmqctl set_permissions -p <vhost_name> <user> ".*" ".*" ".*"
# 重启
sudo rabbitmqctl restart
第二步:编写服务器代码server.py
from celery import Celery
app = Celery('tasks', backend='amqp',
broker='amqp://<user>:<password>@<ip>/<vhost>')
def add(x, y):
return x + y
并在服务器执行:
celery -A server worker --loglevel=info
第三步:编写客户端代码
1.task.py
from server import add
result = add.delay(4, 4)
print(result.get(timeout=1))
2.server.py
from celery import Celery
app = Celery('server',backend = 'rpc://',broker='amqp://<user>:<password>@<ip>/<vhost>')
@app.task
def add(x, y):
# return x + y
pass
并在客户端执行:
python task.py
即可看到本地输出:
8
服务器输出:
[2019-11-12 16:18:06,145: INFO/MainProcess] Received task: server.add[0455eccf-b81e-46d4-9b19-b511d8e1a93e]
[2019-11-12 16:18:06,147: INFO/ForkPoolWorker-1] Task server.add[0455eccf-b81e-46d4-9b19-b511d8e1a93e] succeeded in 0.0005705989897251129s: 8
以上。
阅读全文 »
Python中的装饰器
2019-11-12
有时候在看python源码的时候会看到在方法上面有个@的标识,这就是是装饰器。 装饰器提供了一种修改方法或类的灵活性,可以在不改变或者不必了解方法或者类的内部实现的基础上修改方法或者类。 比如:
from flask import Flask
app=Flask(__name__)
@app.route('/')
def hello():
return 'hello'
上述代码表示hello方法以及参数’/’需要传入@声明的方法app.route()执行。
等同于
rule = "/"
view_func = hello
# They go as arguments here in 'flask/app.py'
def add_url_rule(self, rule, endpoint=None, view_func=None, **options):
pass
阅读全文 »
xpath的语法简介
2019-07-08
xpath用于XML解析,也可以用于HTML网页的解析。
对于HTML的解析概括起来就是:找到HTML中某个节点上下左右前后节点,然后对这些节点进行取值。
所以本文的思路就是介绍如何使用xpath对目标节点上下左右前后节点的选择。包括以下内容:
- 所有节点
- 根节点
- 父节点的选择
- 子节点的选择
- 前面的节点的选择
- 后面的节点的选择
语法
在正式介绍之前首先介绍的是xpath的语法。
xpath的语法和文本的路径类似,比如在ubuntu中某个路径为/home/user/data,这表示根目录下home文件夹下user文件夹下的data文件夹。同理,xpath中/表示根节点,而//表示文档中所有节点。
/node表示根下的node节点
//node表示文档中的所有node节点
所有节点
所有节点的选择通过*进行。
比如要选择某个节点下的所有节点,表示为//node/*。
父节点和子节点
父节点表示当前节点的上一级节点。比如node节点的父节点表示为//node/parent::*。
子节点表示当前节点的下一级节点。比如node节点的子节点表示为//node/child::*。
祖先节点和孙节点
祖先节点表示从根节点到当前节点的所有上级节点(不包括本节点)。比如node节点的祖先节点表示为//node/ancestor::*。
孙节点表示当前节点的所有下级节点(不包括本节点)。比如node节点的孙节点表示为//node/descendant::*。要包括本节点使用//node/descendant-or-self::*。
兄弟节点
兄弟节点表示跟当前节点同级的节点。
比如某个节点前面的所有兄弟节点(不包括本节点)//node/preceding-sibling::*。
比如某个节点后面的所有兄弟节点(不包括本节点)//node/following-sibling::*。
前后所有节点
父子节点,祖孙节点区别在于,父子节点只是对直属上下级节点的选择;祖孙节点在于从根节点到当前节点的所有节点的选择。
而前后所有节点的选择,在于除去从根节点到本节点外的所有前后节点。
前面所有节点的选择(不包括本节点)表示为//node/preceding::*。
后面所有节点的选择(不包括本节点)表示为//node/following::*。
属性操作
下面的内容介绍另一种选择节点的方法。
//node[1]:node节点的第一个//node[last()]:node节点的最后一个//@id:包含id属性的节点//node[@id]:node节点中包含id属性的节点//node[@*]:node节点中包含属性的节点//node[not(@*)]:node节点中不包含属性的节点//node[@id='b1']:node节点中包含属性id,值为b1的节点//node[normalize-space(@id)='b1']:去除属性值中的空格//*[count(node)=2]:包含node子节点超过2的节点//*[name()='node']:节点名为node//*[starts-with(name(),'B')]:节点名以B开头//*[contains(name(),'C')]:节点名包含C//*[string-length(name()) = 3]:节点名长度等于3//node1 | //node2:选择node1和node2的并集
阅读全文 »
如何打造一个个人微博爬虫
2019-07-07
本文介绍使用scrapy爬虫框架打造一个自己的微博客户端。主要包括以下内容:
- 1.介绍如何分析构造微博爬虫;
- 2.使用scrapy进行网页内容提取。
1.分析如何构造爬虫流程
对于大不多数爬虫,首先考虑的应该是从手机端入手,因为手机端的网页相对PC端来说内容更为简洁,并且爬起来容易许多。所以本文爬取的就是微博的手机端网站:https://weibo.cn/。 为了构造所需的爬虫,首先需要分析目标网站的网站结构。以微博为例,打开微博手机端网站输入密码登陆之后进入的就是首页。首页上的内容就是关注的人发布的微博。比如下图:
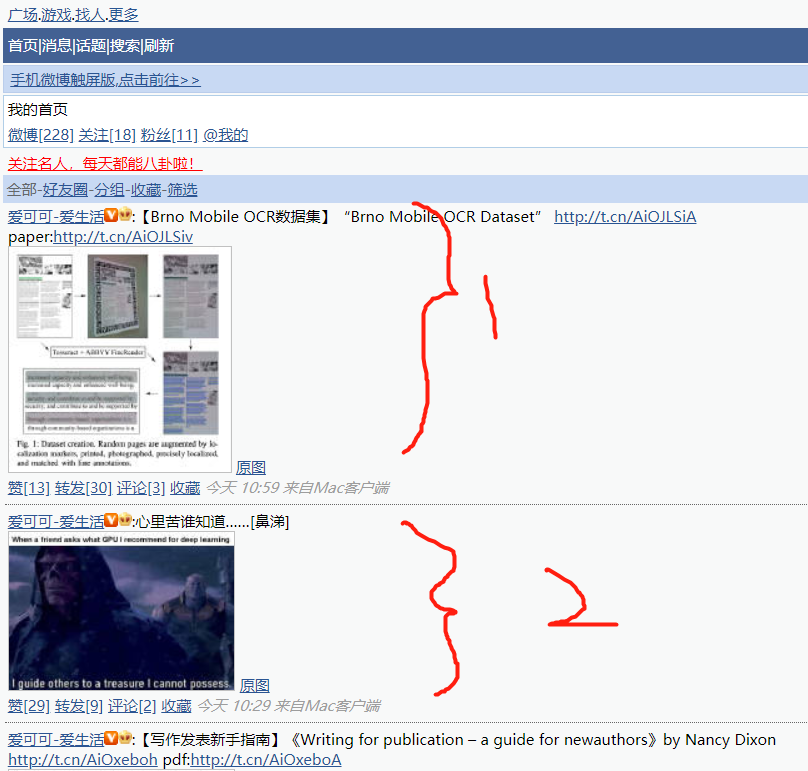
红色的数字1、2就是指一条条关注的人发布的微博。
到这里,一个简单的爬取思路就出来了:首先是打开网址;然后是登陆首页;最后就是按照页码顺序把一条条微博提取出来。
用流程图表述为:
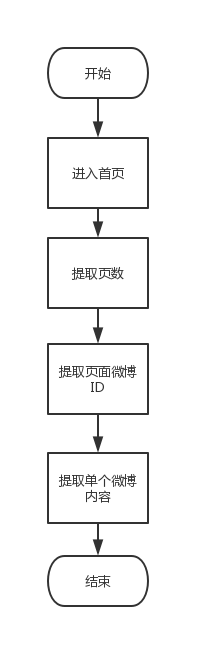
2. 使用scrapy进行网页内容提取
本文对微博手机端的分析使用的是Chrome浏览器自带的工具。在浏览器按下F12即可打开。如下图所示:
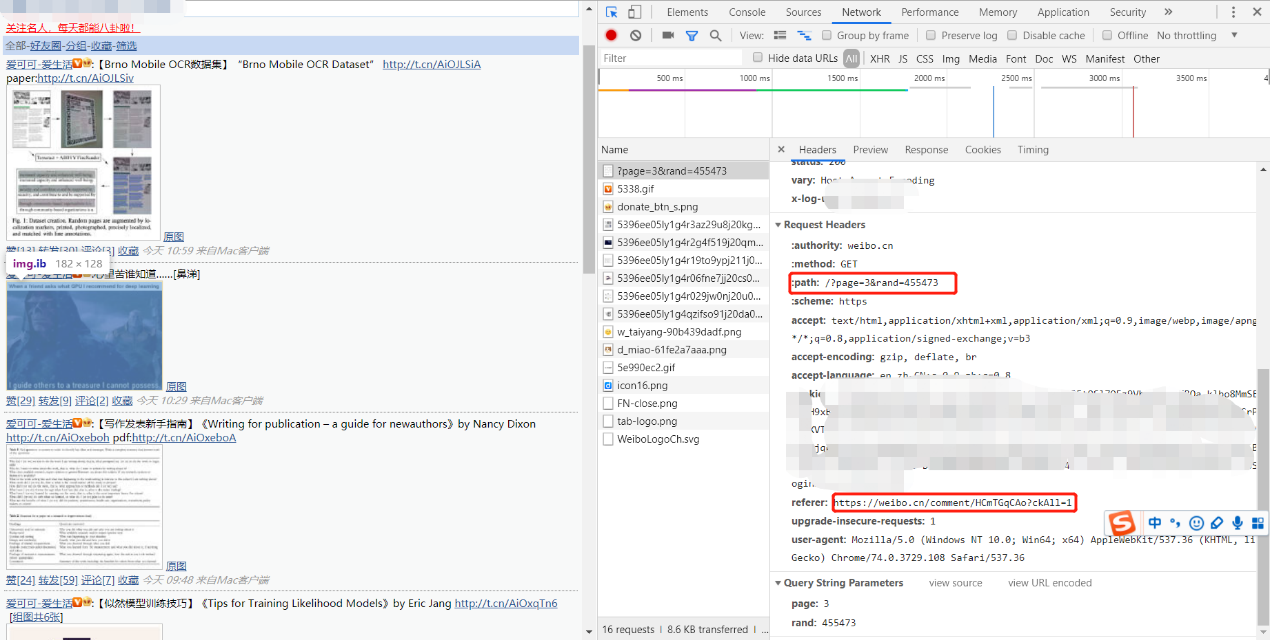
由上图可以得出以下结论:
-
- 个人主页的微博页面的网址构造为:https://weibo.cn?page=页码
-
- 微博ID对应的页面为:https://weibo.cn/comment/ID
-
- 自动登录的cookie(图中模糊部分)
打开任意一条微博ID的页面:
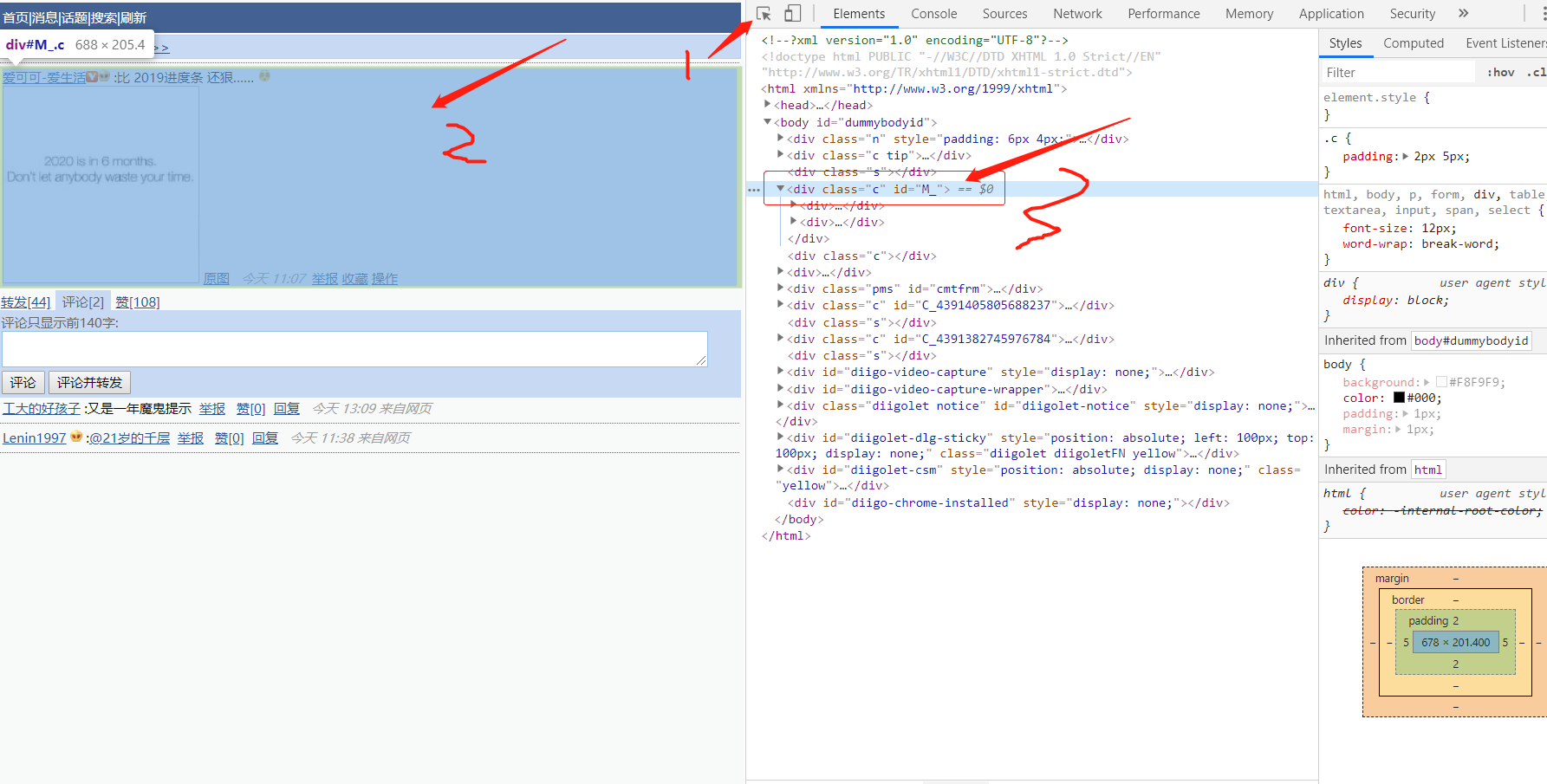
按照上图的箭头点击顺序,可以看到微博内容的标签为<div class=’c’ id=’M_’>,因而根据标签就可以提取到微博的内容了。
上述几个步骤用代码表述为:
def parse(self, response):#解析页码
page_num=0
if response.xpath("//input[@name='mp']") == []:#这里处理微博为空的情况
page_num = 1
else:
page_num = (int)(response.xpath("//input[@name='mp']")[0].attrib['value'])
# https://weibo.cn/?page=2
for i in range(1,page_num+1):#page 1-40
yield response.follow(f'https://weibo.cn/?page={i}', callback=self.parse_id)
def parse_id(self,response):#提取对应页码的微博ID
ids=response.xpath('//div[contains(@id,"M_HC")]/@id').getall()
for id in ids:#parse weibos
#https://weibo.cn/comment/HAwmslrRT
yield response.follow(f'https://weibo.cn/comment/{id.replace(r"M_","")}', callback=self.parse_weibo)
def parse_weibo(self,response):#提取对应微博ID的内容
content=response.xpath('//div[@id="M_"]')[0].xpath('string()').extract()[0]
self.writer.write(content+'\n\n')
以上介绍了构建个人微博客户端的关键步骤,具体可以参考gihtub上的开源代码。